Project’s Rationale
In December 2003 the BioSec project, co-funded by the VI Framework Programme of the European Commission, started its two years life cycle with the purpose to consolidate and progress research on biometric technologies.
Biometric technologies provide automated means to identify a subject according to physiological or psychological features. These technologies have a high potential to guarantee the identity of the individuals and they appear as the key technologies to provide trust and secure access to private information. Nevertheless, this technology is not completely consolidated or accessible with the required features in security, trust and confidence to the public nowadays. This is due to several factors such as the lack of standards defining the communication and data models to guarantee the security and integrity of the exchanged information, the lack of maturity of the technology with the consequent vulnerability to fake and security attacks, the lack of technological solutions to guarantee the privacy and ownership of the biometric data, or the incompatibility among biometric components, devices, systems, and data available in the market. All these factors contribute to a low usability and acceptance by the citizens. BioSec has the challenge to solve these problems by working in several clearly defined action lines.
BioSec is the project that will bring deployment of a European-wide approach to biometric technologies for security applications. It has the support of the European Commission and a consortium, led by Telefónica I+D, with twenty three organizations from nine countries (Belgium, Finland, France, Greece, Germany, Israel, Italy, Poland and Spain). This consortium constitutes a critical mass in the Biometric area including big companies like Siemens, Telefonica, Grupo ETRA, Atmel and G&D, biometric hardware and software producers, prestigious universities and SMEs with large experience in the field of biometrics. BioSec will develop biometric technologies for secure smart card and USB token based digital identification systems, which provide the levels of trust and confidence necessary for citizens to interact either physically or remotely with any organization or service requiring secure and authenticated identification.
It will provide a ‘digital me’ for the European citizen. From the technological point of view, BioSec will provide improved performance to: novel 3D face and hand method, noise-cancellation based voice verification method, as well as with emphasis on multimodal biometrics, including face-voice and iris-finger combinations used together with advanced classification methodology. Fake-resistive methods will be developed for high security fingerprint and iris verification.
In order to put the biometric technologies in the final user’s hands –the citizen– and increase their confidence in them, the results of the research activities to be carried out in BioSec are directed to produce personal biometric storage on smart cards and personal privacy portable devices. New ID tokens will be addressed on BioSec objectives. Interoperable token devices, integrating biometric information (of any modality that is in BioSec agenda) in a secure and tamper-free solution will enable a new generation of devices that will transform the user privacy concept into a real concept, under user control.
As BioSec is a Research Technology and Development project on pan-European scope, it has defined an efficient strategy for the wider dissemination of its results and achievements. Several communication channels have been established to be present at different levels: creation of an observatory on those standardization activities related to the biometric technologies, creation of a web site with updated information on the project progress (www.biosec.org), organization of bi-annual open workshops to present and discuss the project achievements, participation in scientific conferences and events, publication of articles and white papers, etc.
Research Objectives
BioSec is an Integrated Project (IP) where Biometrics and security play together to leverage trust and confidence in a wide spectrum of everyday applications. Partners from nine countries constitute a critical mass in the Biometric area (including big companies, biometric HW/SW producers, prestigious universities and SMEs).
Recent investigations carried out in Europe and the USA (BioVision, BKnC) identified the main deficiencies that yielded to a certain underdevelopment of Biometrics with respect to its potentialities and to ten-years-ago goals. BioSec will address most of these open issues and will provide the basis for improving and developing new sensors, algorithms, procedures and applications, towards the AmI Space, with new security requirements in an open environment. In particular, research will be focused on these issues: scientific/technological (such as 3D biometrics and aliveness detection); user-centred (acceptance, usability and legal framework); and application-related (such as secure interoperable biometric tokens and remote authentication).
Performance evaluation will be conducted throughout the whole project in a sound and statistically relevant way, under a specifically-created committee control. Significant efforts will be devoted to contributions to standards, co-operation with existing organizations (such as NoE), and to dissemination of the results.
BioSec activities include development of demonstrators in various scenarios (such as airport security and remote authentication) for which important final users have been already involved. Other technology deployments will be made during the project lifetime, driven by the first successful research results; the participation of big industrial partners (with big customers) ensures a very large catchment area.
A strong management with well established roles and responsibilities will ensure proper decisions to be promptly taken in order to successfully drive the project towards its ambitious objectives.
Our Contribution
Improving discriminant analysis for face verification
A novel algorithm that can be used to boost the performance of face authentication methods that utilize Fisher’s criterion is presented. The algorithm is applied to matching error data and provides a general solution for overcoming the “small sample size” (SSS) problem, where the lack of sufficient training samples causes improper estimation of a linear separation hyper-plane between the classes. Two independent phases constitute the proposed method. Initially, a set of locally linear discriminant models is used in order to calculate discriminant weights in a more accurate way than the traditional linear discriminant analysis (LDA) methodology. Additionally, defective discriminant coefficients are identified and re-estimated. The second phase defines proper combinations for person-specific matching scores and describes an outlier removal process that enhances the classification ability. Our technique was tested on the M2VTS and XM2VTS frontal face databases. Experimental results indicate that the proposed framework greatly improves the authentication algorithm’s performance.
Description of Algorithm
We propose a framework for using discriminant techniques that can overcome the small sample size problem, after face verification matching features are extracted by an elastic graph matching algorithm for face verification. Elastic graph matching is based on the analysis of a facial image region and its representation by a set of jets which are local descriptors (i.e. feature vectors) extracted at the nodes of a sparse grid:
![]() ,
,
where ![]() denotes the output of a local operator applied to image
denotes the output of a local operator applied to image![]() at the
at the ![]() scale or the
scale or the ![]() pair (scale, orientation),
pair (scale, orientation), ![]() defines the pixel coordinates and
defines the pixel coordinates and ![]() denotes the dimensionality of the feature vector. The grid nodes are either evenly distributed over a rectangular image region or placed on certain facial features (e.g., nose, eyes, etc.) called fiducial points. The core of the elastic graph matching is to translate and deform the reference graph on the test image in order to find the correspondences of the nodes of the reference graph on the test image. That is accomplished by minimizing the same cost function that employs node jet similarities and preserve the node relationships.
denotes the dimensionality of the feature vector. The grid nodes are either evenly distributed over a rectangular image region or placed on certain facial features (e.g., nose, eyes, etc.) called fiducial points. The core of the elastic graph matching is to translate and deform the reference graph on the test image in order to find the correspondences of the nodes of the reference graph on the test image. That is accomplished by minimizing the same cost function that employs node jet similarities and preserve the node relationships.
The algorithm that was developed in order to enhance the face verification performance of an arbitrary elastic graph matching algorithm can be summarized in the following two steps:
- Weigh the similarity values at the nodes of the elastic graphs by coefficients that derive a multiple local discriminant analysis scheme.
- Weigh the classification scores that are derived by matches done on multiple reference images of the same subject by using discriminant analysis.
The first step of our algorithm is to find a person specific discriminant transform of the new local similarity values and create the total similarity measure. Let be a column vector comprised by the new local similarity values at every node. The algorithm should learn a discriminant function that is person specific and form the total similarity measure between faces:
. 
During this stage of the algorithm, traditional LDA was found to sometimes degrade the classification performance because of the SSS problem where the dimensionality of the samples is larger than the number of available training samples. A novel alternative method was used to define the discriminant weighting vector that is used to form a total similarity, or distance, measure between the reference face and a test person, as such:

Specifically, was calculated by implementing the following procedure:
- For claims related to each reference person , grid nodes that do not possess any discriminatory power are identified and discarded.
- In order to provide better estimation to Fisher’s linear discriminant, the between-class scatter matrix is redefined so as to accommodate the prior probabilities of how well the mean of each class – client or impostor – was estimated. Thus, the so called weighted between-class scatter matrix is formed.
- In order to give remedy to the SSS problem each matching vector is broken down to a number of smaller dimensionality vectors of equal lengths. Thus, subsets are formed and separate LDA processes are carried out. For the XM2VTS data, the optimum value for the length of these subsets is found and used. In addition, discriminant coefficients that are badly estimated due to a small training set, or due to any large non-linearity between corresponding subsets, are identified and re-estimated in an iterative fashion, if needed.
- Each of the weight vectors produced, having smaller dimensionality than the original feature vectors, is normalized so that their within class variance equals to one. This normalization step enables the proper merging of all the subset weight vectors to form the overall weight vector .
During the second step of the algorithm that was developed, the set of matching scores that correspond to each person’s reference photos is used in a supplementary discriminant analysis step. Once again, the modified Fisher’s criterion that uses the weighted between-class scatter matrix is used. In particular, person specific weights, , are calculated for the scores, corresponding to reference person images, for the problem that is formulated as such:
In addition, this step is complemented by an outlier removal process related to the number of the minimum impostor matching scores in the training set of each reference person. Successively, the final verification decision that is a weighted version of the sorted matching scores is produced.
Evaluation Process
The XM2VTS database contains 295 subjects, 4 recording sessions and two shots (repetitions) per recording session. The data is divided in three different sets the training set, the evaluation set and the test set. The training set is used to create client and impostor models for each person. The evaluation is used to learn the thresholds. In order to evaluate the DEGM algorithm the ‘Configuration I’ experimental setup of the XM2VTS database was used. For this configuration the training set has 200 clients, 25 evaluation impostors and 70 test impostors. The training set of the Configuration I contains 200 persons with 3 images per person. The evaluation set contains 3 images per client for genuine claims and 25 evaluation impostors with 8 images per impostor. Thus, evaluation set gives a total of 3 × 200 = 600 client claims and 25 × 8 × 200 = 40.000 impostor claims. The test set has 2 images per client and 70 impostors with 8 images per impostor and gives 2 × 200 = 400 client claims and 70 × 8 × 200 = 112.000 impostor claims. For the M2VTS database the Brussels protocol was implemented that employs the ‘leave-one-out’ and ‘rotation’ estimates, and a total of 5,328 client claim tests and 5,328 impostor claim tests (1 client or impostor x 36 rotations x 4 shots x 37 individuals) were carried out.
Results
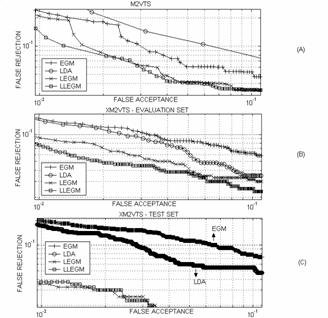
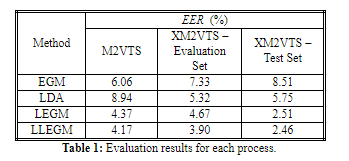
Let us call the combination of the morphological elastic graph matching, EGM, and the weighting approach that makes up for the first phase of the proposed algorithm, as is described in the previous section as LEGM. Moreover, let LLEGM be the second phase of our algorithm. In order to evaluate the performance of these methods the False Acceptance (FAR) and False Rejection (FRR) rate measures are used. Figure 1-A shows a critical region of the ROC curves for the raw EGM data using (4), classical LDA (7) applied on the raw EGM data, LEGM and LLEGM evaluated on the M2VTS database. Figure 1-B shows the same corresponding ROC curves when the algorithms were evaluated on the XM2VTS evaluation set and Figure 1-C the corresponding ones for the XM2VTS test set. Results are presented in logarithmic scales. In addition, Table 1 shows the equal error rates (EER) for each algorithm, a common face authentication evaluation measure that is specified as the point where FAR and FRR are identical. The evaluation tests on the two databases show that for both FAR and FRR, LEGM is indisputably a better performer than either EGM or LDA while LLEGM almost always provides additional improvement to the classification ability of LEGM.
BioSec Partners:
Telefónica Investigación y Desarrollo S.A.U. (Spain); Sisäasiainministeriö (Ministry of the Interior Finland); Finnair Plc (Finland); Tampereen Yliopisto: University of Tampere (Finland); VTT Electronics (Finland); Biometrika SRL (Italy); Universita Di Bologna (Italy); Etra I+D (Spain); Universidad Carlos III de Madrid (Spain); Universidad Politecnica de Madrid (Spain); Universitat Politecnica de Catalunya (Spain); Ibermática S.A. (Spain); Universität zu Köln (Germany); MediaScore Gesellschaft für Medien- und Kommunikationsforschung mbH (Germany); Siemens AG (Germany); Giesecke & Devrient Gmbh (Germany); ATMEL Grenoble S.A. (France); Centre for Research and Technology Hellas (Greece); Expertnet A.E. (Greece); Aristotle University Of Thessaloniki (Greece); VCON Telecommunications Ltd. (Israel); Naukowa i Akademicka Siec Komputerowa: NASK (Poland); Katholieke Universiteit Leuven (Belgium).