Project’s Rationale
VISNET (Networked Audiovisual Media Technologies) is a European Network of Excellence funded under the 6th framework programme. Its strategic objectives are revolving around its integration, research and dissemination activities of networked audiovisual media technologies applied to home platforms. The focus of the research activities are mainly the creation/coding of AV content for immersive home platforms, storage and transport of AV information over heterogeneous networks, audiovisual analysis techniques for immersive communications and security of AV content and transmissions.
Partners:
- University of Surrey
- Fraunhofer Institute for Telecommunications, Heinrich-Hertz Institute
- Ecole Polytechnique Fédérale de Lausanne
- Instituto Superior Técnico
- Aristotle University of Thessaloniki
- Universitat Politecnica de Catalunya
- Joint Research Centre
- Thales Research and Technology
- Technical University Berlin
- Vodafone Ltd
- France Telecom R&D
- Universitat Pompeu Fabra
- Politecnico di Milano
- Warsaw University of Technology
- Instituto de Engenharia de Sistemas e Computadores do Porto, Portugal
Our Research Objectives
AUTH’ s research objectives contain the following tasks:
- sharing platforms for conducting research aims at enabling the common use of resources and research facilities.
- Scene segmentation and classification using audio features.
- Speaker-based Segmentation.
- Speech Modelling.
- Audio Segmentation which concerns the coarse or scene segmentation of an audio stream (e.g. silence / speech / music / noise), as well as finer level of sound classification (male/female, types of noises, music genre, etc.).
- Speaker Segmentation.
- Investigation of probabilistic frameworks for face detection and tracking that show robustness to occlusions and invariance to illumination changes.
- Detection of facial features which aim to develop intelligent semantic segmentation and tracking techniques for natural.
- A software tool for hand-labelling of video sequences. The tool allows for interactive labelling feature points and areas of interest in each video frame and outputs the corresponding information in text files. The main functionality of this tool is to generate ground truth data to be used for evaluating the performance of tracking algorithms.
- Development of watermarking techniques.
Contributions of AUTH
Scene Change Detection using Audiovisual Clues
AUTH has developed a method for scene change detection. The method exploits both audio and video information. Unlike shot changes, a scene change is most often accompanied by a significant change in the audio characteristics, usually in the characteristics of background noise. In the proposed method, audio frames are projected to an eigenspace that is suitable for ‘discovering’ the changes in the audio track caused by the variations of background audio. An analysis explains why the selected subspace is suitable for detecting scene changes Video information is used to align audio scene change indications with neighboring shot changes in the visual data by considering certain timing restrictions. It has been found that such an alignment can reduce the false alarm rate. Moreover, video fade effects are identified and used independently in order to track scene changes. The detection technique was tested with very good results on newscast videos provided by the TRECVID 2003 video test set. The experimental results show that the aforementioned methods that are used to process the audio and video information complement each other well when tackling with the scene change detection problem. For this specific test additional work can be done, using news-specific knowledge, in order to secure higher detection results.

Figure1. Subspace investigation for the proper formation of the projection components set. Determine which eigen-vectors best explain the variations of the background noise.



Figure 2. Detected shot cuts and fades using video information; the corresponding fade effect is shown.
Moreover a technique for detecting shot boundaries in video sequences by fusing features obtained by two shot boundary detection methods that have been proposed by AUTH. The first method relies on performing singular value decomposition on a matrix created from 3D color histograms of single frames. The method can detect cuts and gradual transitions, such as dissolves, fades and wipes. The second method relies on evaluating mutual information between two consecutive frames. It can detect abrupt cuts, fade-ins and fade-outs with very high accuracy. Combination of features derived from these methods and subsequent processing through a clustering procedure results in very efficient detection of abrupt cuts and gradual transitions, as demonstrated by preliminary experiments on TRECVID2004 video test set containing different types of shots with significant object and camera motion inside the shots.

Figure 3. Plot of the first and second dimension of the feature vector depicting the dissolve pattern between two shots (the dense clusters) in a video sequence.

Figure 4. Recall-precision curves for the three methods tested in the experiments.
Watermarking polygonal lines using Fourier descriptors
A novel blind watermarking method for vector graphics images through polygonal line modification has been developed by AUTH as a continuation and enhancement of research that has been conducted prior to VISNET. In the developed method the coordinates of the vertices are changed. The watermark is embedded in the magnitude of the curve’s Fourier descriptors to exploit the location, scale, and rotation invariant properties of these descriptors. Watermark detection is blind, i.e., the watermark detection procedure doesn’t need the original polygonal line and is performed by a correlation detector. Due to the Fourier descriptor properties, the watermark is detectable even after rotation, translation, scaling, smoothing or reflection attacks. The method can be used for the IPR protection of vector graphics images (e.g. cartoon images and maps in vector representation) through the watermarking of polygonal lines that appear in these images. Potentially it can be also used for the watermarking of raster images (especially cartoon images that include large homogeneous regions) by segmenting the images, watermarking the contours that delineate the segmented regions and rasterizing again the watermarked regions. The proposed method can be also used in higher order B-spline contour watermarking.


Figure 5. Map used in our experiments with the (a) original polygonal line and (b) watermarked line.

Figure 6. ROC curves for all the attacks for the polygonal line in Figure 5.
Furthermore , a method for blind 3D mesh model watermarking has been proposed by AUTH. The method has been designed so as to be invariant to 3D translation, scaling and mesh simplifications. Invariance to these geometric transformations is obtained by aligning the model before embedding and detection through the following sequence of steps: a) evaluating the center of mass and the principal components (eigenvectors) of the 3D vertices that make up the mesh b) rotating and translating the mesh prior to embedding so that its center of mass and principal components coincide with the origin and the axes of the coordinate system c) performing the same transform on the data prior to detection . The actual embedding is performed by modifying the radial component of the vertices in a spherical coordinates representation so as to enforce appropriate constraints in neighbourhoods of vertices. Detection is subsequently performed by checking the validity of these constraints. The method is also sufficiently robust to mesh simplification due to the fact that each bit of the pseudorandom watermarking sequence is embedded in more than one vertices (redundancy). The method can be used for the IPR protection of 3D geometric models used in computer graphics and animation. Experimental results indicate the ability of the proposed method to deal with various attacks. An example is shown in Figure 7.


An audio watermarking technique based on correlation detection, where high-frequency chaotic watermarks are multiplicatively embedded in the low frequencies of the DFT domain is investigated by AUTH. High pass signals have been shown to posses better correlation properties than white and low-pass signals. The suggested watermarking scheme guarantees robustness against lowpass attacks, along with preservation of the good correlation properties and thus, enhancement of the detector reliability. The class of the piecewise-linear Markov chaotic watermarks and in particular, the skew tent maps are utilized. Their major advantage is their easily controllable spectral/correlation properties. The efficiency of the proposed approach will be demonstrated using a large number of experiments and tests against various attacks.
Coordinate descent iterations in pseudo affine projection algorithm
Another one contribution of AUTH in VISNET is the introduction of a new affine projection algorithm based on the dichotomous coordinate descent algorithm. A generalization for simplified Volterra filters is also made and its stability is improved by using a voice activity detector. The proposed algorithm has a fast convergence, low complexity and behaves well in a double-talk scenario. The performance of the proposed algorithms for nonlinear acoustic echo cancellation is assessed.

Figure 8.a) The speech signal and the voise activity detector decision. b) echo return loss enhancement of a generalization for simplified Volterra filters on high (solid line) and normal (dotted line) volume levels; c) Improvement achieved over normalized mean square error using a 3th order simplified Volterra filter , in the same situations.
Evaluation of tracking reliability
An important issue that was investigated by AUTH was objective ways for measuring the performance and reliability of feature-based tracking algorithms. In most cases the tracking techniques are judged using subjective evaluation methods. In certain cases quantitative evaluations based on ground truth data are performed. The implementation of reliability measures that do not resort to ground truth data but are capable of measuring the tracker performance especially in cases of rapid performance degradation such as partial or total occlusion has been investigated. More specifically, evaluation of the efficiency and experimental comparison of three tracker reliability metrics, applicable to feature-based tracking schemes has been performed. Two of the metrics used for the metrics construction are based on information theory and namely are the mutual information and the Kullback-Leibler distance. The third one is based on normalized correlation. In the context of the evaluation frame, the metrics were applied on an object tracking scheme using multiple feature point correspondences. Experimental results have shown that the information theory based metrics behave better in partial occlusion situations than the normalized correlation based metric. A clear distinction in performance between the two information theory based metrics cannot be easily extracted. The Kullback-Leibler distance seems to provide more smooth curves. Nevertheless, the mutual information has the advantage of being unique and symmetrical. One set of experiments is shown in Figures 9 and 10.




Figure 10. Values of the metrics versus frame number are depicted for the artificial image sequence of Figure 9. (a) Mutual information, (b) Kullback-Leibler distance and (c) normalized correlation.
A monocular system for automatic face detection and tracking
AUTH has also developed a complete functional system capable of detecting people and tracking their motion in either live camera feed or pre-recorded video sequences. The system consists of two main modules, namely the detection and tracking modules. Automatic detection aims at locating human faces and is based on fusion of color and feature-based information. Thus, it is capable of handling faces in different orientations and poses (frontal, profile, intermediate). To avoid false detections, a number of decision criteria are employed. Tracking is performed using a variant of the well-known Kanade-Lucas-Tomasi tracker, while occlusion is handled through a re-detection stage. Manual intervention is allowed to assist both modules if required. In manual mode, the system can track any object of interest, so long as there are enough features to track.

Figure 11. Schematic diagram of the detection and tracking algorithms

Figure 12. Schematic diagram of the detection and tracking algorithms

Moreover, a novel approach for selecting and tracking feature points in 2D images is under development by AUTH. The method selects salient feature points within a given region and proceeds in tracking them over the frames of a video sequence. In this method, the image intensity is represented by a 3D deformable surface model. Selecting and tracking are performed by exploiting a by-product of explicit surface deformation governing equations. The proposed method was compared with the well known Kanade- Lucas- Tomasi (KLT) tracking algorithm, in terms of tracking accuracy and robustness. The obtained results show the superiority of the proposed method



Figure 14. The initial facial image, its surface representation and the deformed model which wraps image intensity surface.

Figure 15. 300 feature points were selected on a facial image.
Table 2. Mean and Variance of the Euclidean distance (error) in pixels between feature points tracked by the two algorithms and ground truth data. Each algorithm is initialized with its own feature points.
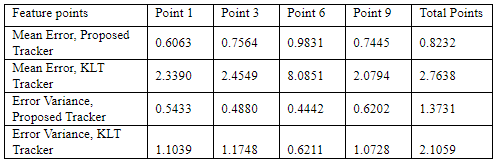
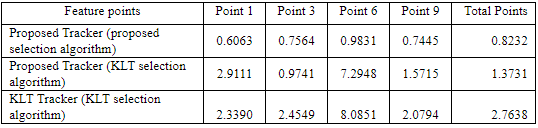



Figure 16. Results of the feature based tracking algorithm applied on a face.
OBJECT TRACKING BASED ON MORPHOLOGICAL ELASTIC GRAPH MATCHING
In the filed of object tracking, AUTH has also developed a novel method for real-time tracking of objects in video sequences. Tracking is performed using the so-called Morphological Elastic Graph Matching algorithm. When applied to faces, initialization of the tracking algorithm is performed by means of a novel face detection and facial feature extraction step. The obtained results show good performance in scenes with complex background. Comparison with an existing feature-based tracking method using measures based on ground truth data proves the superiority of the proposed method. . Future work could include the testing of the method on video sequences with more than one subject, therefore an efficient way of handling partial or total object occlusion should be devised.

Figure 17.The multiscale dilation (sub-images 2-8) and erosion (subimages 9-15) of a facial image (sub-image 1), using a circular structuring function for scale parameter values 1-7 respectively.

Figure 18. The Morphological Elastic Graph Matching Tracking algorithm.

Figure 19. Tracking results of the proposed algorithm for a 500-frame segment of a video sequence. Sample frames taken at 100-frame intervals.
EMOTIONAL SPEECH CLASSIFICATION USING GAUSSIAN MIXTURE MODELS AND THE SEQUENTIAL FLOATING FORWARD SELECTION ALGORITHM
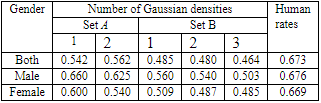
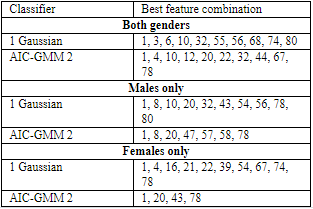
AUTH has also proposed a procedure for reducing the computational burden of crossvalidation in sequential floating forward selection algorithm that applies the t-test on the probability of correct classification for the Bayes classifier designed for various feature sets. For the Bayes classifier, the sequential floating forward selection algorithm is found to yield a higher probability of correct classification by 3% than that of the sequential forward selection algorithm either taking into account the gender information or ignoring it. The experimental results indicate that the utterances from isolated words and sentences are more colored emotionally than those from paragraphs. Without taking into account the gender information, the probability of correct classification for the Bayes classifier admits a maximum when the probability density function of emotional speech features extracted from utterances corresponding to isolated words and sentences is modeled as a mixture of 2 Gaussian densities.